The Health Privacy Challenge
| Participate in the new Track II (Blue Team🫐) featuring: OneK1K Single-Cell Gene Expression Dataset! Visit ELSA Benchmark platform for details and to access the dataset. |
📢 Computational health research is centered on sensitive health-care data, including genomic, medical and phenotypic data. Progress in the field hinges on the ability to access these data to advance health care using analytical innovations, while simultaneously ensuring that sensitive information of data subjects is not disclosed.
Synthetic data generation is one of the well-adopted approaches to enable privacy preservation through generating data points that are consistent with the distribution of the real data. Generative models, such as Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN), can be used for this purpose, allowing to generate synthetic data that maintains the utility of original data while protecting privacy. However, the effectiveness of synthetic data generators in biology, and the extent to which they can protect against adversarial attacks, such as membership inference risks, remain underexplored.
The Health Privacy Challenge, which is organized in the context of the European Lighthouse on Safe and Secure AI (ELSA, https://elsa-ai.eu), invites participants to advance this field by contributing in a “Blue Team (🫐) vs Red Team (🍅)” scheme:
- The blue teams develop privacy-preserving generative methods to generate synthetic gene expression datasets that are able to balance the biological utility and privacy,
- The red teams assess the privacy risks that these generative methods might pose by developing novel and effective membership inference attack (MIA) techniques,
While both teams explore robustness and reliability of evaluation metrics in the context of privacy preservation in synthetic biological datasets.
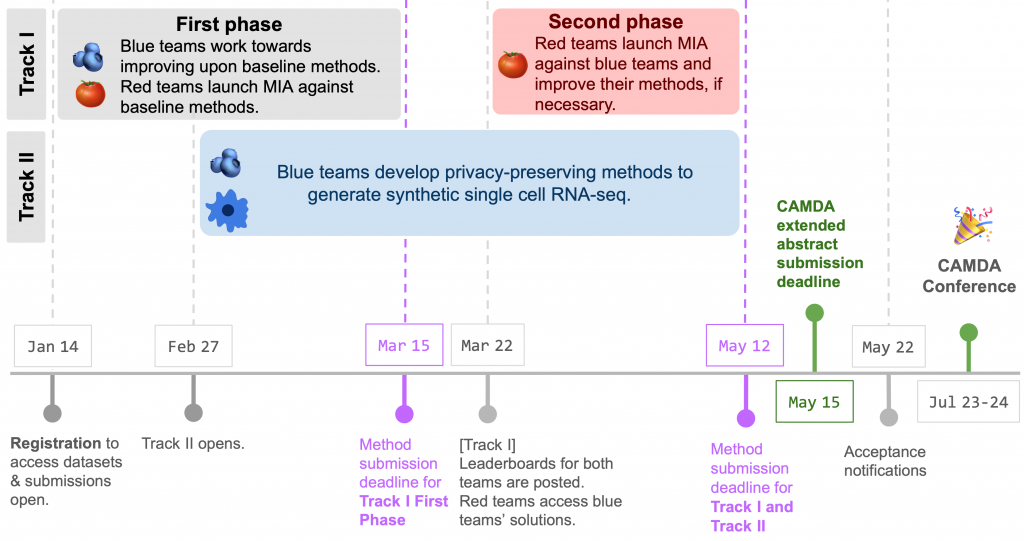
🧩 Challenge Structure: The Health Privacy Challenge consists of two phases, where Blue and Red team members must participate in benchmark method submissions.
Phase 1:
- (🫐) Blue teams work towards developing methods that improve the baseline generative methods and generating novel insights into privacy preservation in biological datasets,
- (🍅) Red teams launch membership inference attacks (MIA) against the synthetic datasets, generated by the baseline generative methods.*
Phase 2:
- After the end of Phase 1, a set of Blue team solutions will be selected, based on their leaderboard performance as well as novelty of their methods.
- (🍅) During Phase 2, in which only Red teams participate, Red teams will launch MIA against these selected Blue teams’ solutions.
* MIA aims to re-identify the training data points used to generate synthetic datasets from the original dataset. This re-identification process pertains only to identifying the pseudo-identities within the dataset and does not, in any way, attempt to re-identify the original donors.
🎢 Participation: In order to successfully participate in the challenge, the participants must,
- Register through ELSA Benchmark Platform to access the challenge datasets and detailed instructions. We recommend you to register using an organizational email if possible.
- Submit their methods (codes and relevant files) through the ELSA Benchmark Platform.
- (🫐) Blue teams must participate in benchmark submission by the Phase 1 deadline.
- (🍅) Red teams must participate in two benchmark submissions by the Phase 1 and Phase 2 deadlines.
- Submit a CAMDA extended abstract that details their benchmark method submissions during Phase 1 and 2 by the CAMDA submission deadline. ( Both teams (🫐,🍅) ).
We provide a Github Starter Package Repo for both teams, which includes baseline methods and evaluation metrics, as well as guideline to base their method developments on.
🗂️ Datasets: We re-distribute two open access TCGA bulk RNA-seq datasets in the pre-processed form, which can be accessed from the GDC portal (portal.gdc.cancer.gov) as raw counts. Each donor in the datasets has a single sample.
- TCGA-BRCA: Breast cancer dataset of size <1,089 (donors) x 978 (genes)> with five subtypes, suitable for cancer subtype prediction task;
- TCGA COMBINED: A collection of ten different cancer tissues of size <4,323 (donors) x 978 (genes)>, suitable for cancer tissue-of-origin prediction task.
More details about the datasets and preprocessing steps can be found at ELSA Benchmark Platform and Github Starter Package Repo.
🏆 Evaluation: The teams with the best solutions will be determined based on multiple criteria, including,
- 🎯 leaderboard ranking,
- 💡 novelty of methods,
- 🌱 generation of novel insights into privacy-preservation in biology.
Therefore we strongly encourage the participants to submit their CAMDA extended abstracts to be evaluated even if they might not have achieved a high ranking on the leaderboards.
The winners of the blue and red teams will be invited to present their methods at the CAMDA Conference at ISMB 2025, and will be awarded with travel fellowships sponsored by ELSA.
⏳ Timeline:
🎉 Get started:
- Please visit the ELSA Benchmark Platform to register and to access the datasets. Detailed information about benchmark method submissions can also be found here.
- Visit the Github Starter Package Repo to reproduce baseline generative and membership inference methods, and further instructions.
- Make sure to connect with us in the CAMDA Health Privacy Challenge Google Groups for questions, discussions and to follow the upcoming announcements!
We are looking forward to engaging with both members of the computational biology and the privacy community, and working together to deepen our understanding of privacy in health care. 🤗